
Une récente Correctif Linux publié par DMLA a révélé que le calcul GPU de la nouvelle génération Instinct MI200, nom de code « Aldébaran« , utilisera un conception de modules multi-puces (MCM). Cela signifie que le GPU sera livré avec deux matrices dans un seul paquet au lieu de la matrice unique à laquelle nous sommes habitués avec les GPU standard. L’accélérateur est basé sur leArchitecture d’ADNc 2 et sera utilisé dans le Supercalculateur Exascale Frontier qui sera achevé plus tard cette année.
Le patch se lit comme suit :
Sur Aldebaran, seule la matrice primaire récupère des données d’alimentation valides. Il affiche les valeurs de puissance / énergie comme 0 sur le dé secondaire. De plus, la limite de puissance n’a pas besoin d’être définie via la matrice secondaire.
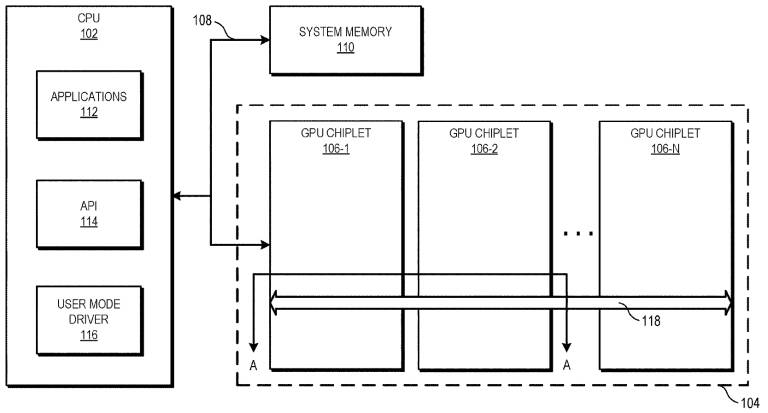
AMD a déposé un brevet intitulé « Chiplet GPU utilisant des liaisons croisées à large bande passante« , Comme l’a noté Coelacanth-dream, la société travaille donc depuis un certain temps déjà sur sa technologie multi-puces pour le calcul du GPU. De plus, selon le correctif Linux, la technologie GPU MCM d’AMD nécessite que l’une des puces devienne la principale et gère le reste, ce qui aiderait le GPU multi-puces à ressembler et à se comporter comme un grand processeur pour le système hôte.
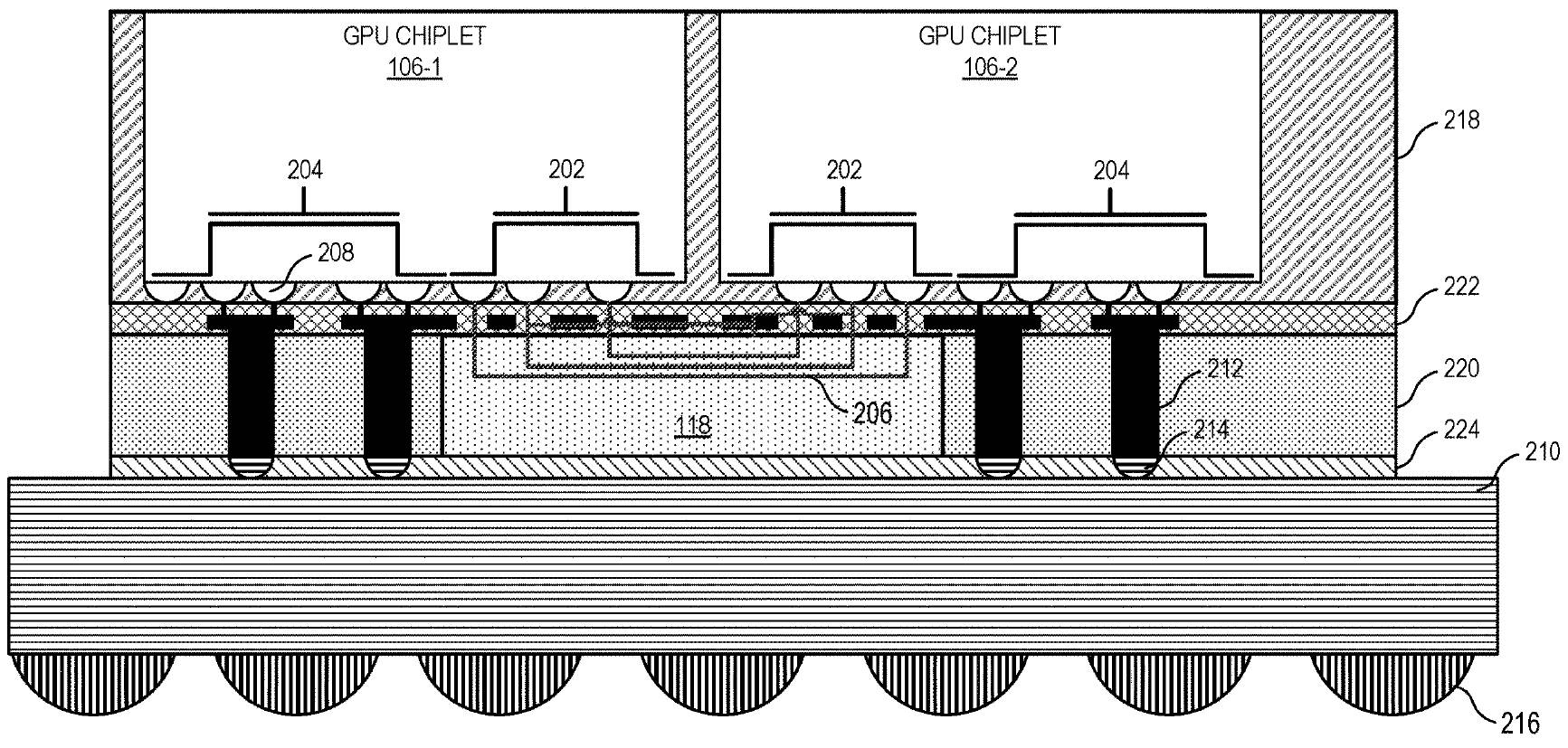
Construire un calcul GPU, c’est comme construire un processeur MCM multicœur, comme des processeurs Ryzen 5000 ou alors Déchiqueteuse. Tout d’abord, la proximité des matrices augmente l’efficacité de calcul. Deuxièmement, il est plus facile de produire en masse des puces plus petites à l’aide d’une technologie de traitement avancée que les grandes, car les appareils plus petits ont généralement moins de défauts, ce qui vous donne un rendement plus élevé.
Bien que les sous-systèmes graphiques multipuces n’aient jamais été très populaires, car de nombreuses charges de travail graphiques ne peuvent pas évoluer efficacement, le fait d’avoir plus de calculs GPU sur les serveurs permet une augmentation considérable des performances en raison de la nature parallèle des charges de travail des centres de données. De toute évidence, les applications doivent être conçues pour tirer le meilleur parti de ces types d’architectures, mais il semble qu’un large soutien de l’industrie pour MCM émerge car les GPU Xe-HP et Xe-HPC d’Intel sont également basés sur cette conception. De plus, il semble que les prochains calculs GPU Hopper de NVIDIA soient également équipés de plusieurs matrices.
Crédit : AMD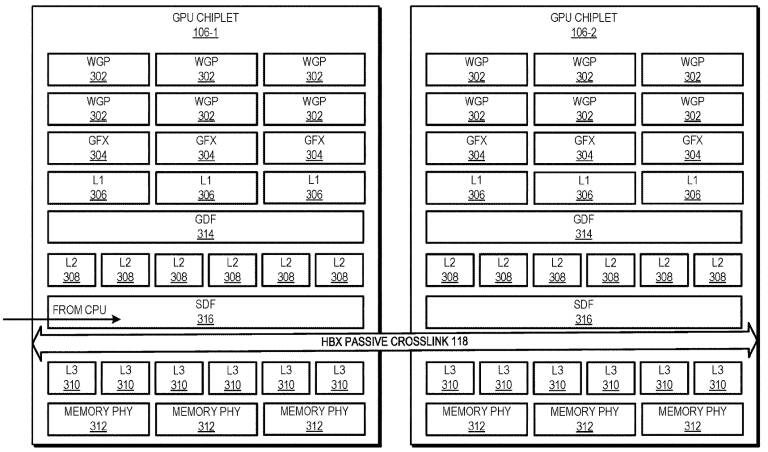
HPE, partenaire d’AMD, a confirmé que le prochain supercalculateur Frontier, qui sera le plus rapide au monde offrant des performances de pointe de 1,5 ExaFLOP, utilisera le processeur « Trento » (très probablement une version de Milan avec un cache supplémentaire et / ou d’autres améliorations) et les accélérateurs Instinct MI200.
Vous cherchez une bonne carte mère à coupler avec les nouveaux processeurs Ryzen ? ASUS ROG Strix X570-F avec 14 phases d’alimentation pourrait être un bon choix. Vous pouvez le trouver sur Amazon à un bon prix.





{kind=link}